It's very simple: Who has the ability and motive to do this? I don't think it's a mechnic error. computer works as it originally designed. It won't make an error on a particular case.
1. A hacker.
2. The staff of Google.
3. The perpetrator who create Sandy Hook shooting.
I think the purpose is to meddel the water to confuse people. Government monopolized the news agency. Theycensored the important news of Sandy Hook shootings. Sandy Hook - Judge sealspolice records for 90 days. It helps to fume suspicion of people. Why did theyrelease so much inconsistent information on Sandy Hook shooting?
Do you know why they released the following news(MANY 9-11 "HIJACKERS" ARE STILL ALIVE)? Because there are manypeople work for government as informants. They are afraid of becoming sacrificeswhen they were told to carry out a mission. So the late news (hijackers stillalive) released to comfort them. Now we saw so many disinformation releasedlater after Sandy Hook shooting. It hints "we didn't kill that manychildren". That's the trick how the government fool you the people.
MANY 9-11 "HIJACKERS" ARE STILL ALIVE.
The world's media has reported that many of theso-called hijackers "fingered" by the FBI are still alive. Forexample the BBC (British Broadcasting Cooperation) carried this report:
Actually, none of the above. It's really quite simple why it happens, but first you need to understand a couple of things:
- How Google and other search engines index pages
- How dynamic pages work
Google uses what is called a
web crawler, which is literally a program that visits every page of a domain(e.g. youtube.com) as defined by their
robots.txt file located at the root of the domain(visit
http://youtube.com/robots.txt to see YouTube's robots.txt, which determines exactly how Google, and other web crawlers following the same standard, should index the site).
In the case of Google, they have thousands of instances of their crawler bot running on a multitude of servers, scanning every domain they know of, 24/7. Unrelated: this crawling actually puts a good deal of load on smaller sites that host a large amount of content, because unlike regular people visiting their site Google is requesting everything they host in a short span of time.
Now, the majority of the web today is dynamic(meaning every time you visit a page, things may be different). Metabunk or any forum is a great example of this. Google, or any other search engine for that matter, has no way of knowing when a page changes because it would require the developer(s) of these dyanmic websites to incorporate some code that informs Google when changes are made, which is actually a lot more complicated than it sounds.
So there we have it - the reason we get erroneous dates like this is because
Google is taking a guess as to the publish date for those pages.
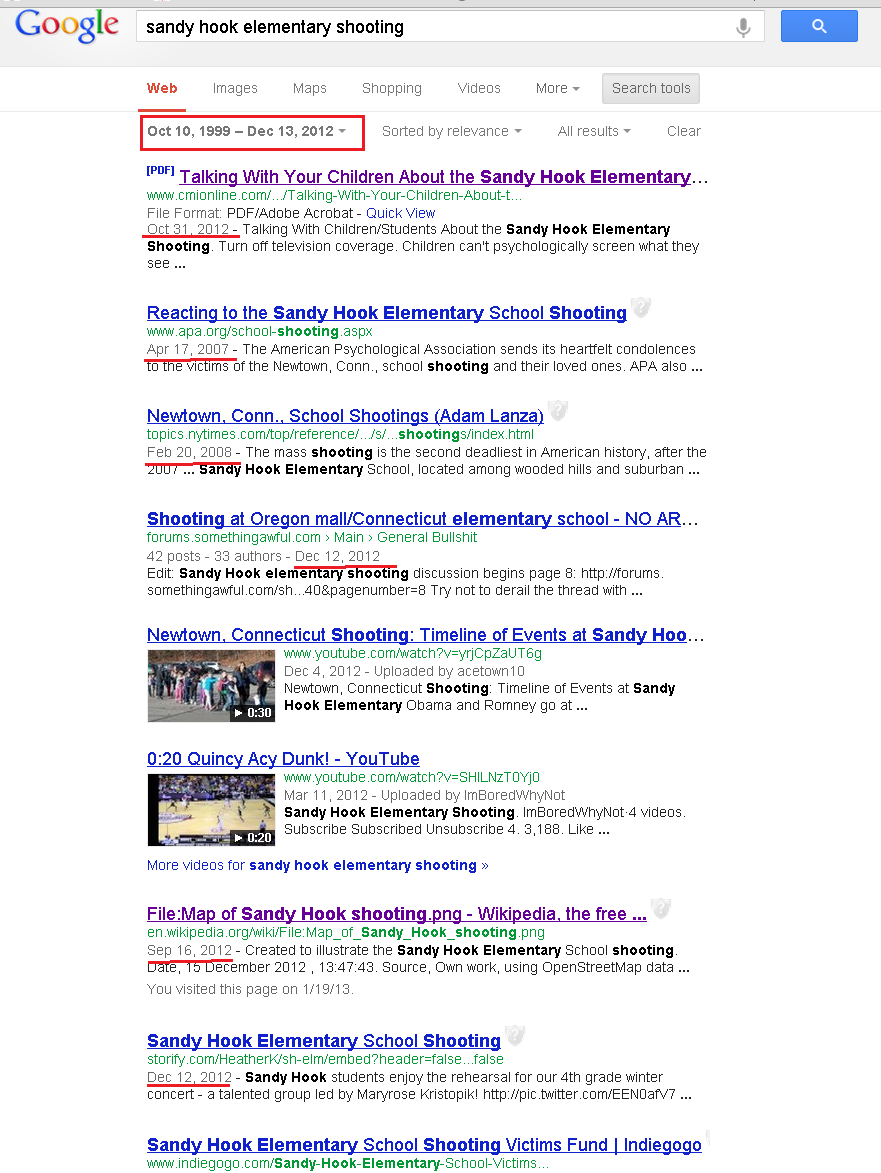
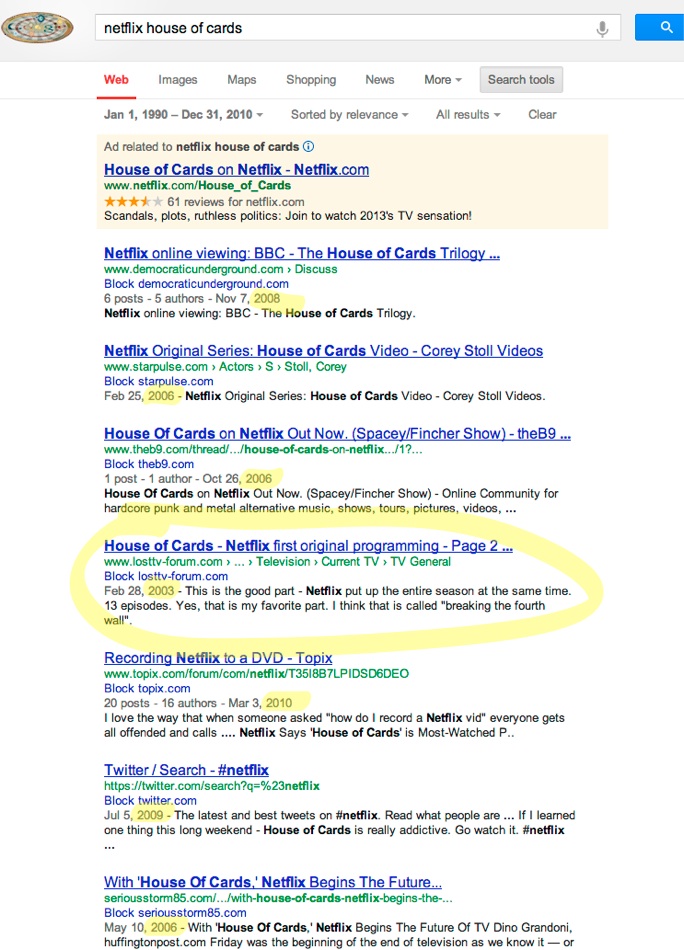
Go ahead and try any date range spanning many years up to the day before the Sandy Hook shooting, and any combination of words pertaining to the shooting. You'll find near limitless results with dates that seemingly indicate the pages were created well before the shooting. You can try this for any other event since Google began indexing pages(~1999 or so) and you will get the same result.
You've posted the second part before, so I think you are just trolling now.

") is almost 100% the same. The opposite to both is "fabrication" in thise instance, since what we speak of is people creating Truths, not distorting truth.
is almost 100% the same. The opposite to both is "fabrication" in thise instance, since what we speak of is people creating Truths, not distorting truth.