
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Subpixel Motion Tracking: Methods, Accuracy, and Application to Video of Collapsing Buildings
- Thread starter benthamitemetric
- Start date
-
- Tags
- motion tracking



OneWhiteEye
Senior Member
Yes, easy.So it could track this: (Which AE can track fine)
Correct. It will give you the center of what's left on the screen.But not this (Which AE also cannot track off the bottom)
It can track this. There will be some distortion if I let it grab the blended parts. as you would expect. Here's what the color contours look like as it passes over the bars:Or this: Which AE can track fine.
The black showing through will distort the measurement if it's included. How much it does so when the weighting is the square of intensity, I don't know. Although, with a context like this I'd undoubtedly latch on to only one pixel color and do equal weighting of the selected pixels. That's still around 5000 pixels so should be decent resolution.
I'll do runs with different settings to see how the results differ. Right now, I'm in the midst of a ground-up rewrite of code to handle general cases as I'd done in the past; can only do one frame at a time and there are a few bugs at the edges so bear with me. One of the features is graphical tracking output in addition to numbers. Calculated position as dot, bounding box of included pixels, and crosshairs showing the center of the bounding box.
When doing selection of only the interior (fixed) color, this is the result for frame 20 (looks a little off but see below):

Single color selection mask used:

I'll probably remove the markup from the mask image, it's just a debug thing right now. Speaking of which, don't pay too much attention to the positioning of the dot, not sure it's correct yet. Everything is in flux. I only have weak color-based rules right now. Give me several days before any final tests are done. Selection mechanism is 95+%, weighting is the rest.
The mask image will probably also be changed so that unused pixels are the same as the original image and the mask color is the most different from the average color of the background. And a second image showing the inverse. This will allow easy determination at-a-glance of how much of the object is thrown away and/or how much background is picked up. Along with the final calculation will be included all significant intermediate results (pixel count, total weight, etc)
Usually I don't get rid of all the background even if it's possible (and many times it isn't). Either way, this situation will introduce error and deviation from the measurements obtained in your first example. It will not track the circle as well with the bars and soon we can compare the deviation. Likewise it will be nice to see how well AE does at the fine level.
OneWhiteEye
Senior Member
Feature Isolation (part 2)
It's everything.
I never said I was selecting a rectangular area, in fact I said otherwise and indicated the reason in the femr2 example was expediency. There are so many ways to tell it what to look for and what to ignore. Selecting a single color is the simplest thing of all and won't work on any real video, but there's plenty of selection rules which will. Once a (discrete) patch of pixels representing the shape of the object is obtained, weighting can take over. As mentioned before, equal weighting alone is a pretty good estimate of its geometric center, if the mask is good.
Again, feature selection is really just weighting. Exclusion is zero confidence. I treat selection and weighting distinctly in implementation so tend to think of them as different things. The excluded pixels in masking amounts to discarding the low-hanging rotten fruit. First thing is crop to the rectangular area of interest, which is the smallest rect fully containing the feature plus a few pixel's margin of background. Then apply color selection, which results in an arbitrary shape, but hopefully one closely matching the feature.
There are other ways besides color to refine selection, including things which may depend on the context of the scene/feature or even the specific frame. Most of which can be automated and incorporated into a general parameterized framework if desired, but some special intervention is sometimes required. I consider a minimally functional setup to include keyframe interpolation for all the important governing parameters. Keyframes and associated setpoints are always supplied manually.
The distinguishing feature (pun intended) of my method is finding a mean center location using those selected pixels weighted by whatever confidence measure seems best for the problem. There are a lot of cases where such a mean location is a good representative point for location of an object. Sometimes it's the best representative. Where it isn't, the results will go from degraded to worthless on the spectrum. Once it's worse than I could do by eye/hand, I don't use it.
That's most of what I have to say on the subject right now, since writing the code to do it comes before explanation, and other things before that.
It's everything.
I never said I was selecting a rectangular area, in fact I said otherwise and indicated the reason in the femr2 example was expediency. There are so many ways to tell it what to look for and what to ignore. Selecting a single color is the simplest thing of all and won't work on any real video, but there's plenty of selection rules which will. Once a (discrete) patch of pixels representing the shape of the object is obtained, weighting can take over. As mentioned before, equal weighting alone is a pretty good estimate of its geometric center, if the mask is good.
Again, feature selection is really just weighting. Exclusion is zero confidence. I treat selection and weighting distinctly in implementation so tend to think of them as different things. The excluded pixels in masking amounts to discarding the low-hanging rotten fruit. First thing is crop to the rectangular area of interest, which is the smallest rect fully containing the feature plus a few pixel's margin of background. Then apply color selection, which results in an arbitrary shape, but hopefully one closely matching the feature.
There are other ways besides color to refine selection, including things which may depend on the context of the scene/feature or even the specific frame. Most of which can be automated and incorporated into a general parameterized framework if desired, but some special intervention is sometimes required. I consider a minimally functional setup to include keyframe interpolation for all the important governing parameters. Keyframes and associated setpoints are always supplied manually.
The distinguishing feature (pun intended) of my method is finding a mean center location using those selected pixels weighted by whatever confidence measure seems best for the problem. There are a lot of cases where such a mean location is a good representative point for location of an object. Sometimes it's the best representative. Where it isn't, the results will go from degraded to worthless on the spectrum. Once it's worse than I could do by eye/hand, I don't use it.
That's most of what I have to say on the subject right now, since writing the code to do it comes before explanation, and other things before that.
Last edited:
OneWhiteEye
Senior Member
Or this:

Yes, it can do this exceedingly well. Probably a whole lot better than it can do the ellipse on bars. We'll see.
First off, the method for blobs is 2D. When the same sort of calculation is restricted to 1D, it becomes an edge placement routine. There are differences in the treatment of an edge but I consider the method to be a variant on the same thing.
Points and edges are the primitives I can work with. There are so many nice edges in that, and a few good blobs, too. Of course I'll track multiple points, and would have to let some drop off and others start if it displaced much, and then would have to correlate the various tracked points into a rigid displacement (since it is in this case).
Yeah, it's a lot of work to set up. But that's not under dispute.
OneWhiteEye
Senior Member
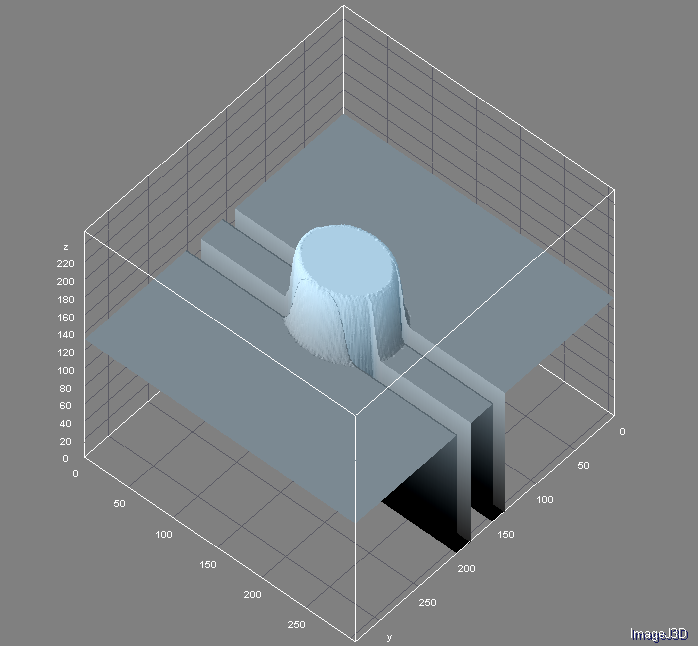
I hope the 3D plots assist in conveying intensity's role in feature distinction. 3D adds no information at all, but maybe it does help when visualizing these as peaks and valleys. The building face above:

LOTS of real nice edges. Let's not forget that black things are targets, too. The inversion of the above:

These are the sweet edges because mostly there are two edges constituting a line - the gradient one direction and then the gradient in the other - so are effectively 1D blobs!
This is an ideal target.
LOTS of real nice edges. Let's not forget that black things are targets, too. The inversion of the above:
These are the sweet edges because mostly there are two edges constituting a line - the gradient one direction and then the gradient in the other - so are effectively 1D blobs!
This is an ideal target.
OneWhiteEye
Senior Member
The building face above is what I previously identified as a compound object; that is, composed of edges and nodes as far as these methods are concerned. There is no recognition of a pattern. I know (or presume) that it is really a single object moving in a rigid fashion and can use that knowledge to advantage. By decomposing the object into its primitives and treating those as individual tracking problems, a large and accurate dataset can be collected and used to derive aggregate x,y motion.
No one would do that when they can point and run in AE/SE, especially when both of those will probably give more accurate results. Multiple points can be run as well and results averaged, if even necessary.
In theory, based solely on my claims for now, this method will do fine on the building. It is real world. Still ideal, but a lot of targets are great.
No one would do that when they can point and run in AE/SE, especially when both of those will probably give more accurate results. Multiple points can be run as well and results averaged, if even necessary.
In theory, based solely on my claims for now, this method will do fine on the building. It is real world. Still ideal, but a lot of targets are great.
OneWhiteEye
Senior Member
I'm working with a number of images as test patterns, some lifted from the internet, some generated artificially. Remember, these are preliminary results. It's being sporadically cobbled together in one script file now.
The black object is a blob as far as I'm concerned:

It has many fine holes which let the background through and is quite mixed up with the background colors towards the periphery. Regardless, it's convex with rotational symmetry so it's a blob. The background changes under every frame; not a lot but the shaded contours and tint change. The object moves and rotates. Here are the output images from that first frame with simple color band selection and equal weighting:

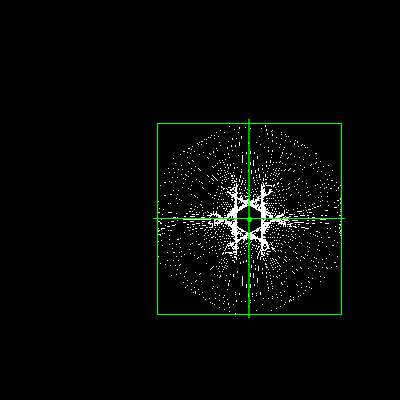
It has a pretty good idea where this thing is without anything too fancy. Mean location doesn't give orientation but it's being treated as a point object. The goal is one number for where it is at any given point. It's strongly desirable for the numbers to mean the same thing across all frames... that will rarely be the case here, but it's part of the enfolded error, or rather how error expresses itself in this scheme.
If I can track the object above, then I can track nanorobots navigating the surface of the eye, and apply this technique to alien abductions as well as 9/11")
The black object is a blob as far as I'm concerned:
It has many fine holes which let the background through and is quite mixed up with the background colors towards the periphery. Regardless, it's convex with rotational symmetry so it's a blob. The background changes under every frame; not a lot but the shaded contours and tint change. The object moves and rotates. Here are the output images from that first frame with simple color band selection and equal weighting:
It has a pretty good idea where this thing is without anything too fancy. Mean location doesn't give orientation but it's being treated as a point object. The goal is one number for where it is at any given point. It's strongly desirable for the numbers to mean the same thing across all frames... that will rarely be the case here, but it's part of the enfolded error, or rather how error expresses itself in this scheme.
If I can track the object above, then I can track nanorobots navigating the surface of the eye, and apply this technique to alien abductions as well as 9/11
So I'm a little confused as to how it is supposed to work. Take the building example
Yes, there are lots of nice features, but how do you track them over multiple frames using the weighted sum of an area to get the center of the area?
I can see how in the small blob on black example, the average gives you the center of the object
And in your above examples, you take advantage of unique colors to isolate an object, which then reduces it to "blob on black".
But with the building, you come up with something to extract a feature, then you have to determine how far it moves from frame 1 to frame 2. How do you know what to extract from frame 2 unless you already know how far it has moved?
Yes, there are lots of nice features, but how do you track them over multiple frames using the weighted sum of an area to get the center of the area?
I can see how in the small blob on black example, the average gives you the center of the object
And in your above examples, you take advantage of unique colors to isolate an object, which then reduces it to "blob on black".
But with the building, you come up with something to extract a feature, then you have to determine how far it moves from frame 1 to frame 2. How do you know what to extract from frame 2 unless you already know how far it has moved?
OneWhiteEye
Senior Member
Roughly, I use the weighted sum method one at a time to get the locations of all the small pieces, then use a composite of those pieces to get the motion of the whole face. It's complicated by rotation, but not unworkable.Yes, there are lots of nice features, but how do you track them over multiple frames using the weighted sum of an area to get the center of the area?
Specifically, I need to ensure that the items measured are really the same items from frame to frame, or at least that any intermediate derived coordinates represent the same points on the building. The edge measurements provide only a mean crossing point through a given pixel slice. Iterating through all viable slices which form an edge gives a path or band representing the mean location of the line segment, which can be fitted to a line. The intersection of two such lines is the corner of a bounding polygon for the object which is composed of the edges.
There's a better way, though, and that's by measuring the blobs first which will give very accurate 2D rotation and translation. This drives selection of the windows as blobs in a second pass, from which bounding boxes are obtained as above. The center of each side then defines a band of edge to search in each of the four faces, likely weighted towards center band. I think you can imagine how it goes from there.
Yes. Subject to interference from the background.I can see how in the small blob on black example, the average gives you the center of the object
Correct. If an object can be distinguished from the background in any way so as to be called a feature, it's by way of color information and that alone. If you can see it with your eyes, software can, too. I can do anything Photoshop (plus operator, to some extent) can do selection-wise - programmatically. Even more probably, since I can introduce any constraint desired for growing or shrinking the selection space. It only has to be good for the problem at hand. It's best to keep it as simple as possible, for a variety ofAnd in your above examples, you take advantage of unique colors to isolate an object, which then reduces it to "blob on black".
Uh... I tell it? Man, I'm over here writing it all from scratch.But with the building, you come up with something to extract a feature, then you have to determine how far it moves from frame 1 to frame 2. How do you know what to extract from frame 2 unless you already know how far it has moved?
OneWhiteEye
Senior Member
Essentially that's it. I don't have to write new code for every case - unless I'm starting with nothing as I was a few days ago. As new situations are encountered, new routines are added which are parameterically controlled and can be tailored to other situations which are similar. I'm writing a lot right now because the old stuff is lost in the aethers.
I do have to configure each case manually, specify the cropping and color parameters and decide on a weighting. Even that can be automated to some extent. When I get keyframes up and running it will only be be necessary to configure for a few frames instead of every frame. At one time I aimed for something more like AE: point at the thing and tell it to follow. Almost got like that for single blobs.
A situation like the building will never be a turnkey process for me. It's a bunch of small measurements that then need to be collated to produce the rigid motion. That collation is a specific instance of a more general procedure of dealing with the category of objects called windowed walls, but I'd never attempt a general routine to handle all such cases.
I do have to configure each case manually, specify the cropping and color parameters and decide on a weighting. Even that can be automated to some extent. When I get keyframes up and running it will only be be necessary to configure for a few frames instead of every frame. At one time I aimed for something more like AE: point at the thing and tell it to follow. Almost got like that for single blobs.
A situation like the building will never be a turnkey process for me. It's a bunch of small measurements that then need to be collated to produce the rigid motion. That collation is a specific instance of a more general procedure of dealing with the category of objects called windowed walls, but I'd never attempt a general routine to handle all such cases.
Last edited:
OneWhiteEye
Senior Member
Although I will say that one 10 minute run of a single light in a window as blob will provide an x-y trace of the building motion which will blow away any attempt to track manually. In fact, if I weren't stacking this up against pro software, that's all I'd do for this. Maybe all the light blobs, just for extra confidence and to resolve any rotation.
It's all relative. When I first met up with Greening, he was taking rulers to old computer screens (CRTs with the curvature). David Benson couldn't even view videos on his computer. That was like walking into a gaggle of blind PhDs with one feeble but working eye.
It's all relative. When I first met up with Greening, he was taking rulers to old computer screens (CRTs with the curvature). David Benson couldn't even view videos on his computer. That was like walking into a gaggle of blind PhDs with one feeble but working eye.
OneWhiteEye
Senior Member
... a single light in a window as blob will provide an x-y trace of the building motion ...
The top interior light cropped and enlarged:


This is a good blob target. Ignore for a moment that this a near-perfect image and that it was made by panning across a still, I know there are issues like the reflection moving across the windows which is problematic. Just take it for what it is, which is a better target than the dishes on WTC1's antenna. So I really could do two of these and the motion in the pixel plane would be fully determined to high accuracy. And it would be quick.
This is what I mean by blobs being all over the place. No matter what the scene, there's usually a viable blob or more than one.
OneWhiteEye
Senior Member
These are now stale questions, pardon if not an issue now.
In your ellipse over bars example, it does interfere significantly unless I select only the flat object color at the highest intensity. Even in that case it interferes because the blending will cause sections to drop off the edge of the ellipse. Not a lot, but it will be apparent I'm quite sure. It is a pretty extreme example (good test!) since the boundaries are sharp and the background goes from quite light to black. Here's a case where real world is easier: if a blob target is good (like the light through the window), the background IS flattish, well-separated intensity-wise, and the variations are noise which averages out.
What matters is if the illumination changes on part of the object or its odd shape causes varying intensity across the surface as it moves/rotates. For the case of something on a building face, moving rigidly or nearly so, a little blob moving with it is not subject to those wild cards. If the target is a spot two feet wide which subtends five pixels, there's really not much that's going to change illumination-wise which doesn't affect the target uniformly as a whole. Entering shadow will sweep across the face. If it does so in two frames, who cares, discard them.
----
For sake of simplicity, I'll use illumination/intensity when talking about weighting, but remember the weight can be other things, like proximity to color or preferred position.
You likely see now that the background matters only to the extent it happens to be co-mingled with the object. The vast majority of the background, save for a minority of pixels, can be eliminated. We need only consider what it it does to disrupt the object at its edges.It would seem to me that it is limited to tracking a feature over a background only if:
1) The total weight of the background is unchanged (realistically meaning it's flat, or finely textured)
In your ellipse over bars example, it does interfere significantly unless I select only the flat object color at the highest intensity. Even in that case it interferes because the blending will cause sections to drop off the edge of the ellipse. Not a lot, but it will be apparent I'm quite sure. It is a pretty extreme example (good test!) since the boundaries are sharp and the background goes from quite light to black. Here's a case where real world is easier: if a blob target is good (like the light through the window), the background IS flattish, well-separated intensity-wise, and the variations are noise which averages out.
It must stay within the region, for sure. The total weight, however, can change. The higher it is, the better potential resolution as more distinct position states can be resolved. Say the sun goes behind a cloud, or someone turns off a light. Ignoring specular highlight change (which can be a problem) and the possibility of it now being too dim, only consider the global illumination change: it will still calculate to the same location even though intensity decreased.2) The total weight of the feature is unchanged (meaning it's always within the analyzed region)
What matters is if the illumination changes on part of the object or its odd shape causes varying intensity across the surface as it moves/rotates. For the case of something on a building face, moving rigidly or nearly so, a little blob moving with it is not subject to those wild cards. If the target is a spot two feet wide which subtends five pixels, there's really not much that's going to change illumination-wise which doesn't affect the target uniformly as a whole. Entering shadow will sweep across the face. If it does so in two frames, who cares, discard them.
----
For sake of simplicity, I'll use illumination/intensity when talking about weighting, but remember the weight can be other things, like proximity to color or preferred position.
OneWhiteEye
Senior Member
The point about black things being targets ties into this and is no small matter. Dark objects, using inverted intensity, are better than light ones. The darker it is, the less subject to illumination issues it is (in the real world).
OneWhiteEye
Senior Member
This scene has a complex background and not a lot to work with.

There are only a few blobs. On the near boat, there's a dark spot:


If the boat were passing across the scene at this distance, I could track well on that blob and it would be a simple job. If the spot got larger or smaller, this would be reflected in change of bounding box. For this spot, there's not enough resolution to get a good distance change measurement, but theoretically it's possible with a good target.
That's right. 3D: theta, phi AND a crude r, from one blob.
Here's another blob, the far boat and a mask obtained:


The geometric center of this boat silhouette is a perfectly fine representative angular coordinate. Better than the bow, if it changes direction. The shadow is a problem. As the water surface moves, there will be fluctuation about the mean. If the boat moves, or the measurement is over a long time, the shadow projection will change and the measurement will be skewed. It might be possible to develop rules to reject the shadow, but there would never would be high accuracy nor a need.
There are only a few blobs. On the near boat, there's a dark spot:
If the boat were passing across the scene at this distance, I could track well on that blob and it would be a simple job. If the spot got larger or smaller, this would be reflected in change of bounding box. For this spot, there's not enough resolution to get a good distance change measurement, but theoretically it's possible with a good target.
That's right. 3D: theta, phi AND a crude r, from one blob.
Here's another blob, the far boat and a mask obtained:
The geometric center of this boat silhouette is a perfectly fine representative angular coordinate. Better than the bow, if it changes direction. The shadow is a problem. As the water surface moves, there will be fluctuation about the mean. If the boat moves, or the measurement is over a long time, the shadow projection will change and the measurement will be skewed. It might be possible to develop rules to reject the shadow, but there would never would be high accuracy nor a need.
OneWhiteEye
Senior Member
Aircraft in the sky are blobs. Despite the variations in background, these are all easy pickins, except for the one at the top getting clipped out of the frame.

All together:

One at a time:


All together:
One at a time:
OneWhiteEye
Senior Member
This one is cars on the street. All of the license plates have been blotted out, but real ones make good blobs, too. Besides that, whole vehicles can be blobs. Ideally the scene would not have traffic this dense.

Take the motorcyclist in the distance -

I see four red blobs, two blue blobs and one green:

It's already partially occluded by the vehicle in front. As established, hiding the object can cause problems for commercial trackers as well. Assume the blobs above aren't occluded for discussion. Of these, I'd probaby work only the blue channel, throwing out the upper blue blob (helmet).
Does this motorcycle look more like femr2's example, or a large swath of building face? There are a lot of real world targets like this. Without smoothing, it's reasonable to believe that AE/SE would track well but would jitter at the finer level, perhaps more than necessary since most "shape" change here would be artifact of small pixel groups at the limits of resolution. Here's a real world example of where my method might produce a better looking raw product. Not a hard job.
Take the motorcyclist in the distance -
I see four red blobs, two blue blobs and one green:
It's already partially occluded by the vehicle in front. As established, hiding the object can cause problems for commercial trackers as well. Assume the blobs above aren't occluded for discussion. Of these, I'd probaby work only the blue channel, throwing out the upper blue blob (helmet).
Does this motorcycle look more like femr2's example, or a large swath of building face? There are a lot of real world targets like this. Without smoothing, it's reasonable to believe that AE/SE would track well but would jitter at the finer level, perhaps more than necessary since most "shape" change here would be artifact of small pixel groups at the limits of resolution. Here's a real world example of where my method might produce a better looking raw product. Not a hard job.
Last edited:
OneWhiteEye
Senior Member
After cropping to the blue blob representing the front of the motorcycle, then subtracting the red and green channels from the blue, this is all that's left:

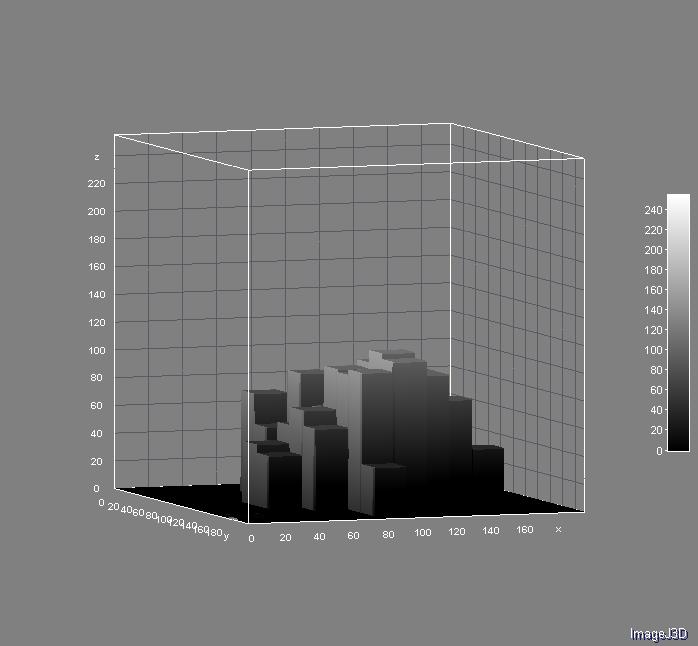
No other masking applied. This can be processed directly as a blob with decent resolution and relative insensitivity to the jitteriness. Probably good enough to give a speeding ticket.
Clearly, everything I've described can be automated. There are a limited set of cues which indicate good target selection, best practice for context, data quality estimates per frame; all of which can be realized in software. And already are by other people. For example, I've used HornetsEye to find corners and edges to within an integer pixel, as reference guides in spatial selection. Color histograms, clustering, why reinvent the wheel?
On the other hand, I did better than HornetsEye frame correlation because it was only nearest pixel.
No other masking applied. This can be processed directly as a blob with decent resolution and relative insensitivity to the jitteriness. Probably good enough to give a speeding ticket.
Clearly, everything I've described can be automated. There are a limited set of cues which indicate good target selection, best practice for context, data quality estimates per frame; all of which can be realized in software. And already are by other people. For example, I've used HornetsEye to find corners and edges to within an integer pixel, as reference guides in spatial selection. Color histograms, clustering, why reinvent the wheel?
On the other hand, I did better than HornetsEye frame correlation because it was only nearest pixel.
OneWhiteEye
Senior Member
Final example in this barrage is one of the taxis from the street image.

The vehicle as a whole is not a blob easily discriminated from its immediate surroundings, but its colored body parts are. Like the motorcycle front end, the uniformed color body parts are subject to specular and direct reflection since they're shiny. The thing is, each part will suffer in a different way, only partially correlated for the most part. Grabbing multiple parts minimizes the impact of variances.
The taxi as green part:


Yellow part:


Orange part:
(no tracking image)
You can see how a lot of the car can be assembled in this fashion. Add edge detection and other geometric and spatial hints (headlights are in such and such proximity to the green and yellow bodies) and most of the car can be re-assembled from scratch, but in distinct groups. The windshield, which will reflect excessively, would be a region with no intensity weighting but could weigh quite heavily in the composite of body parts because it's large and well defined.
The vehicle as a whole is not a blob easily discriminated from its immediate surroundings, but its colored body parts are. Like the motorcycle front end, the uniformed color body parts are subject to specular and direct reflection since they're shiny. The thing is, each part will suffer in a different way, only partially correlated for the most part. Grabbing multiple parts minimizes the impact of variances.
The taxi as green part:
Yellow part:
Orange part:
(no tracking image)
You can see how a lot of the car can be assembled in this fashion. Add edge detection and other geometric and spatial hints (headlights are in such and such proximity to the green and yellow bodies) and most of the car can be re-assembled from scratch, but in distinct groups. The windshield, which will reflect excessively, would be a region with no intensity weighting but could weigh quite heavily in the composite of body parts because it's large and well defined.
OneWhiteEye
Senior Member
The dots, as noted, may not yet be accurately placed. Not verified. The dot need not be coincident with the center of the bounding box and wont be for irregular shapes or some perspectives. This is an additional bit of information for comparison from frame to frame. If they are in roughly the same place, the object is distributed symmetrically. If the spatial relationship between the two is distinct but remains similar or constant, then there's no rotation artifact or certain other problems.
OneWhiteEye
Senior Member
Probably best to do the body panels as outlined areas doing edge detection on the colored-selected shapes, same as the windshield. This minimizes specular interference.
I've been experimenting with toon shading (again) lately, so all this is not so far afield. Weighted sum of toon car areas, Mick.
I've been experimenting with toon shading (again) lately, so all this is not so far afield. Weighted sum of toon car areas, Mick.
Spectrar Ghost
Senior Member
You were holding my rapt attention up until you said "toon car". Then all I could think of was:

Really though, I'm fascinated by your explanation, mostly because it seems so simple. I suspect it is only because you did some smart coding on the front end, but not having too much experience in that field it's pretty cool to watch. That is all.
Really though, I'm fascinated by your explanation, mostly because it seems so simple. I suspect it is only because you did some smart coding on the front end, but not having too much experience in that field it's pretty cool to watch. That is all.
OneWhiteEye
Senior Member
Thank you, I'm glad there's some value. It is simple, in theory. Where is that thing? It's where its colors are.
OneWhiteEye
Senior Member
Actually, the taxi can be effectively handled by subtracting the blue channel from the red and subtracting ~40 to eliminate the background. Here's the result:

Should've known, anything that easy for the eye to distinguish has to be a fricking spotlight to image processing routines. Not a blob, but any rigid object traveling straight a smallish distance through the image would not change aspect much. Good enough probably.
Should've known, anything that easy for the eye to distinguish has to be a fricking spotlight to image processing routines. Not a blob, but any rigid object traveling straight a smallish distance through the image would not change aspect much. Good enough probably.
OneWhiteEye
Senior Member
A similar technique nets the green part.
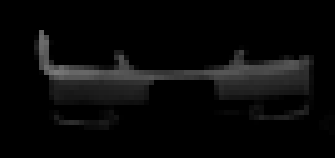
Added together.

Color contrast alone can extract nearly all of the car, eliminating background, making it a composite blob.
Added together.
Color contrast alone can extract nearly all of the car, eliminating background, making it a composite blob.
But what about frame #2? Here you've got a mask for a feature in a single frame. You've found the bounds and center of that mask. You could cookie cut the pixels under the mask to get a different center.
But then what? The mask itself is not sub-pixel.
OneWhiteEye
Senior Member
The masks are generated by my script in some fraction of a second. Running frame #2 is as simple as letting it happen after frame #1.But what about frame #2? Here you've got a mask for a feature in a single frame. You've found the bounds and center of that mask. You could cookie cut the pixels under the mask to get a different center.
But then what? The mask itself is not sub-pixel.
OneWhiteEye
Senior Member
Maybe I don't understand your question. I don't make the mask for the program, the program does the mask for me. The mask is not used. It simply represents the pixels chosen by the algorithm so I can see what it's using.
What do you do for frame #2?
What do you do for frame #2?
The masks are generated by my script in some fraction of a second. Running frame #2 is as simple as letting it happen after frame #1.
Maybe I don't understand your question. I don't make the mask for the program, the program does the mask for me. The mask is not used. It simply represents the pixels chosen by the algorithm so I can see what it's using.
So, Frame #1, you crop, and then use some filter to select some pixel (the masked pixels), and then find the center of those pixels (weighted by luminosity, or some color value)
Frame #2, you repeat, possibly moving the crop rectangle, but using the same filter to generate a new mask. The mask might be different to the mask in step #1?
What do you do for frame #2?
I just let AE run. It's essentially searching frame #2 for the positioning of the feature area that best matches frame #1
OneWhiteEye
Senior Member
It usually will be different from frame to frame. It's not necessary to change the filter specs unless the conditions change. Most times they don't. If they do, say for example the object enters shadow and is now dimmer, okay. I may wish to exclude the few frames of transition, then re-calibrate for the new condition.Frame #2, you repeat, possibly moving the crop rectangle, but using the same filter to generate a new mask. The mask might be different to the mask in step #1?
Suppose instead the scene gets gradually and steadily dimmer. Then I can specify the parameters for the first and last frames and the script will interpolate between those values for each frame. The reason for the pixel count is to determine if any issues like that are occurring. If the object's size and aspect don't change (which is true a lot), the pixel count should remain stable.
It sounds at this point like you're grasping at picayune details. None of the things I've sought to measure were objects flying in and out of shadow, changing shape wildly, or covered in neon and strobe lights. The algorithm practically never needs to adapt to changing conditions as the scene unfolds. It's just not very common. Reason: I don't pick targets like this.
Remember, I'm not attempting to fashion a general purpose machine vision system, rather something that will track targets I choose which are suitable.
Okay, I can't resist. What if it doesn't find it? This is how the question is coming off to me.I just let AE run. It's essentially searching frame #2 for the positioning of the feature area that best matches frame #1
Last edited:
It sounds at this point like you're grasping at picayune details.
No, what I'm trying to determine is how accurate it would be for measuring the fall rates of parts of falling buildings. So i was trying to figure out how it would work beyond the simple "sum the entire image" case. You have provided explanations, but they seem theoretical so far? In terms of actual tracking?
Okay, I can't resist. What if it doesn't find it? This is how the question is coming off to me.
If it does not find it, it will stop tracking. It gives a "confidence" measure for each frame, and you can stop when it gets below a certain level of confidence. You can also manually adjust the tracking regions at any time to get past such problems.
OneWhiteEye
Senior Member
I haven't demonstrated the full-up version yet here because it isn't done. But I will, and I know (how well) it works.No, what I'm trying to determine is how accurate it would be for measuring the fall rates of parts of falling buildings. So i was trying to figure out how it would work beyond the simple "sum the entire image" case. You have provided explanations, but they seem theoretical so far?
Yes, it works in the real world, I've already done it plenty of times. Works great. It was 6-8 years ago and it's a tossup whether it's easier to find and sort out my old code or write new from scratch. I chose the latter, and you're seeing it in progress. But I've done this before.In terms of actual tracking?
Sounds pretty much like the same situation I have!If it does not find it, it will stop tracking. It gives a "confidence" measure for each frame, and you can stop when it gets below a certain level of confidence. You can also manually adjust the tracking regions at any time to get past such problems.
OneWhiteEye
Senior Member
I'll give you a real case where conditions changed. In tracking the antenna, there is a point where it enters shadow of the smoke plume. Up until that point, the dishes were registering as a certain size and after, they were smaller. This is because they dimmed and fewer pixels were being picked up as being above the minimum threshold. However, the background level remained the same so the threshold could not be lowered to pick up those lost pixels at the edge.
Solution: do nothing, let it run. The dishes were projected as uniform orbs, the center was still in the same place. The transition into shadow was a small problem because it swept across from end to the other. So there was a little glitch in the trace.
Solution: do nothing, let it run. The dishes were projected as uniform orbs, the center was still in the same place. The transition into shadow was a small problem because it swept across from end to the other. So there was a little glitch in the trace.
Sounds pretty much like the same situation I have!
Except AE does not have to isolate a "blob" in the scene from a background. In fact you can just select a very large complex region the in the middle of a moving object, like:

Which gives this result:

OneWhiteEye
Senior Member
Right now, the focus is on how I can track an object without the sophisticated algorithms employed by AE/SE. Every little thing that could possibly influence the result is under the microscope. I know there are things which will influence the measurement and produce artifact, not trying to suggest otherwise. There's only so much I can do with a sow's ear as input. Even a measurement of the ellipse over the bars will suffer a small deviation from the true ellipse path due to the bars.
Since I don't have AE or SE, the performance of the sophisticated algorithms are mysterious and somewhat theoretical to me. I get how it's supposed to work, but how well does it actually work? I'm really chomping at the bit to compare on that example. I know my trace will have a divot as it crosses the bars. Does AE? It wouldn't have to, if it were smart enough. It trains on the ellipse when not over the bars, and the bars are stationary. It could ignore the deviations at the edge and report the path as if the bars weren't there, reducing only the confidence, but is that what it does?
Or does it note that the apparent shape of the object has changed for reasons unknown and reports both a lowered confidence AND a less accurate result? If the latter, then I should be asking the same sort of questions about AE. We know it doesn't track the ellipse off the edge of the frame. Why not? It already knows its an ellipse. Can't it just fit the remaining portion of the ellipse to its template grid? Does it only lose it when the point itself being tracked goes off the edge?
If passing over the bars does influence the quality of its measurement, how much error does it introduce?
Since I don't have AE or SE, the performance of the sophisticated algorithms are mysterious and somewhat theoretical to me. I get how it's supposed to work, but how well does it actually work? I'm really chomping at the bit to compare on that example. I know my trace will have a divot as it crosses the bars. Does AE? It wouldn't have to, if it were smart enough. It trains on the ellipse when not over the bars, and the bars are stationary. It could ignore the deviations at the edge and report the path as if the bars weren't there, reducing only the confidence, but is that what it does?
Or does it note that the apparent shape of the object has changed for reasons unknown and reports both a lowered confidence AND a less accurate result? If the latter, then I should be asking the same sort of questions about AE. We know it doesn't track the ellipse off the edge of the frame. Why not? It already knows its an ellipse. Can't it just fit the remaining portion of the ellipse to its template grid? Does it only lose it when the point itself being tracked goes off the edge?
If passing over the bars does influence the quality of its measurement, how much error does it introduce?
Last edited:
OneWhiteEye
Senior Member
Well, yeah, that goes without saying (even though it's been said many times already). AE is easy, general purpose, accepts a wide variety of target types, has the most sophisticated feature matching money can buy, no one's quibbling with any of that.Except AE does not have to isolate a "blob" in the scene from a background.
Your point was that you didn't see how my method could have any use in the real world. I've already shown that it does. I've shown how many targets are in fact blobs in the real world, and how they can be acquired as such. Between blobs and edges, MOST cases are covered, even the building face above. It's just that single blobs are much easier for me.
It it ability/accuracy under dispute now, or application scope and ease of use? Remember all of this digression started with you disagreeing that my process is a better reference standard for an example like femr2's. That's all I claimed, no more or less. Ever since, you've tried to make this into a universal comparison, and that's silly.
My programs will never do what a shrink-wrapped package like AE does. But it IS useful in the real world!
I shall check ....If passing over the bars does influence the quality of its measurement, how much error does it introduce?
It seems like in the bars case then AE has a strange oscillating error of up to 0.22 pixels as it passes over the bars, and that is in the X direction where I would not really expect it.

Probably a knock on result of:
In the Y position, there's seems to be a more 2 pixel wiggle
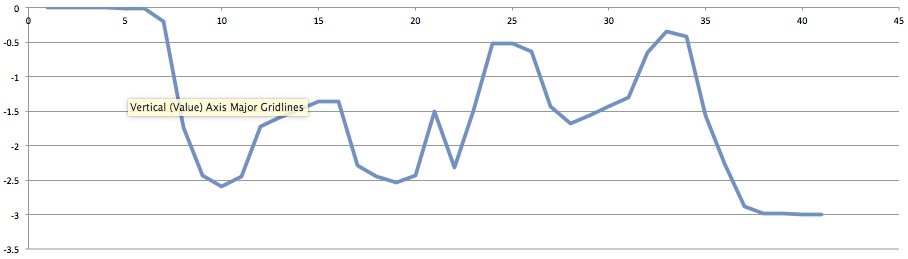
So I guess After Effects cannot really track that case very well.
Probably a knock on result of:
In the Y position, there's seems to be a more 2 pixel wiggle
So I guess After Effects cannot really track that case very well.
Last edited:
Similar threads
- Replies
- 2
- Views
- 825
- Replies
- 13
- Views
- 2K
- Locked
- Replies
- 393
- Views
- 59K
- Replies
- 42
- Views
- 6K