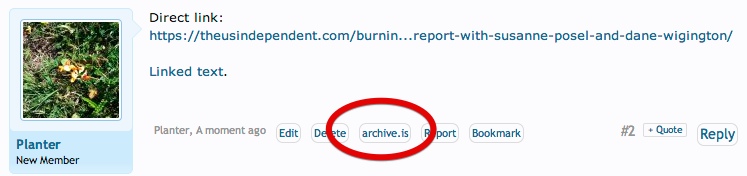
Sometimes you want to link to a page that might change or vanish after a while, particularly if it contains outrageous bunk, or libelous material. Or it might just be something that is by it's nature temporary, like a job posting, or a service request. If you want to make sure you can reference it in the future, then a great free way of doing this is archive.is, a service that will give you both a linked snapshot of the page at that moment in time, and also a .zip version you can use offline, or attach to a post:
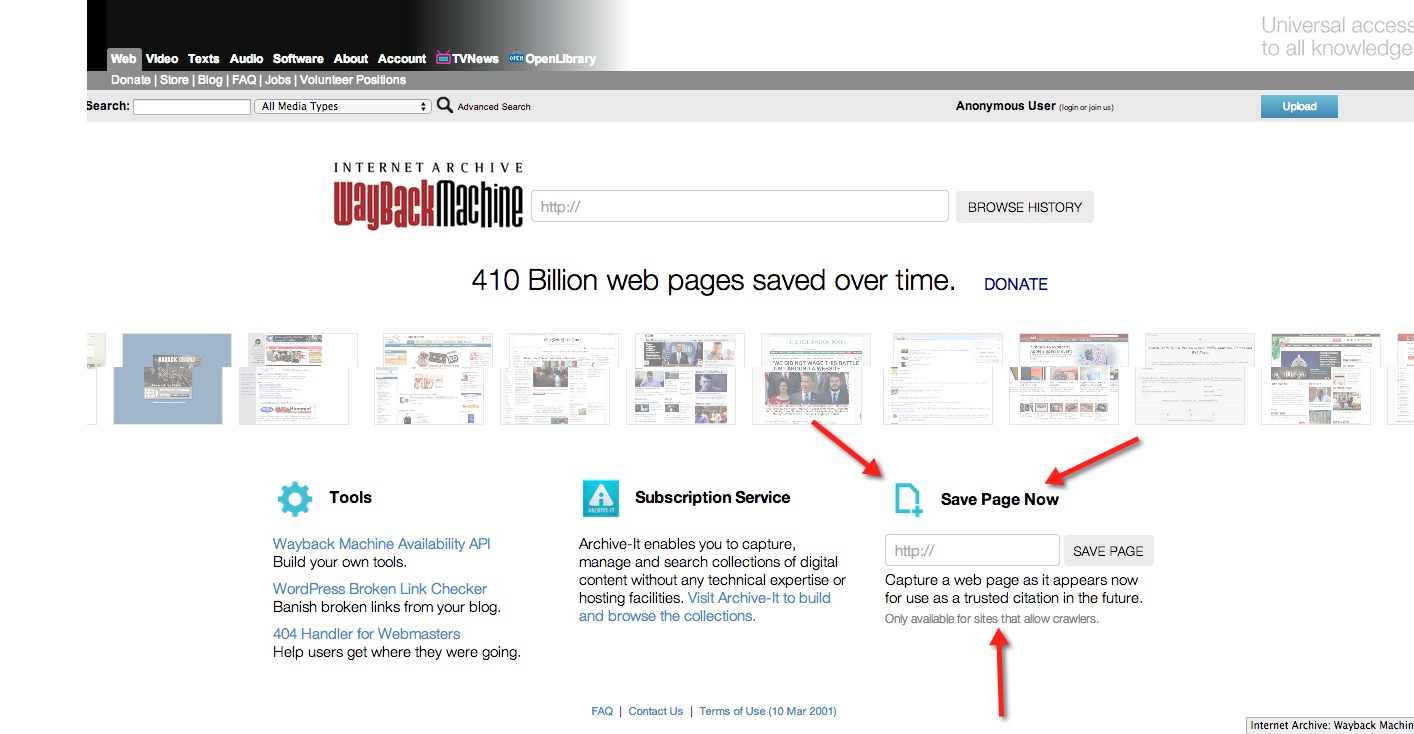
Just copy the URL of the page, then go to:
http://archive.today/ (formerly archive.is, as seen in images below. Currently both URLs work)
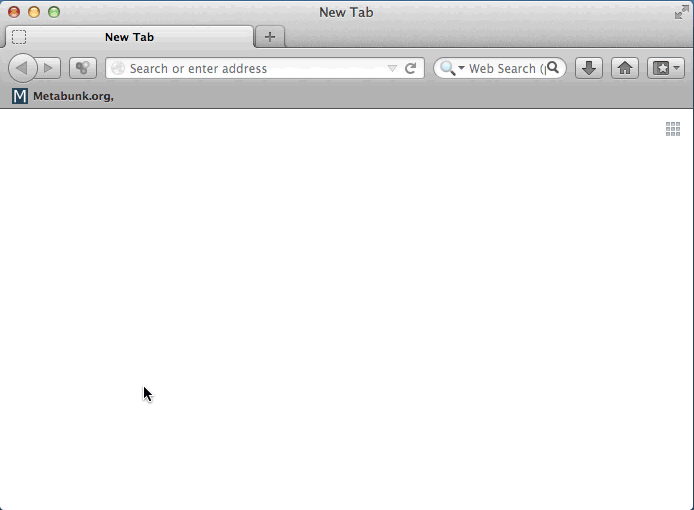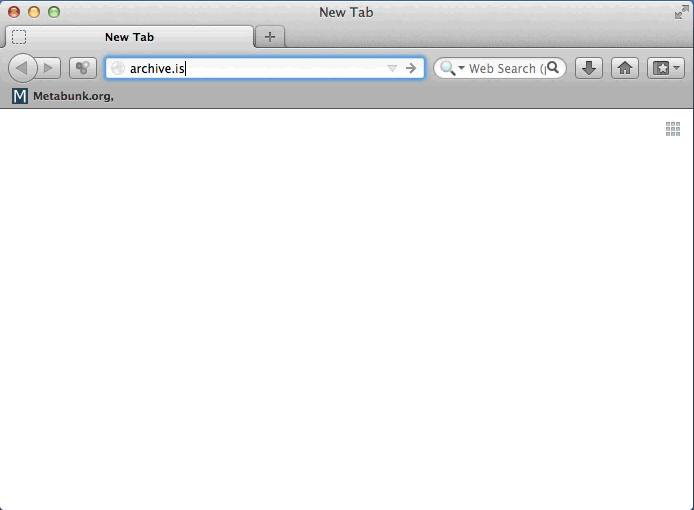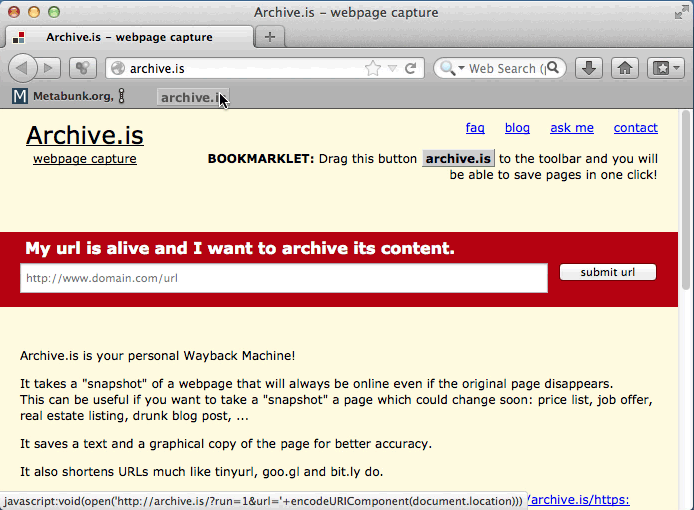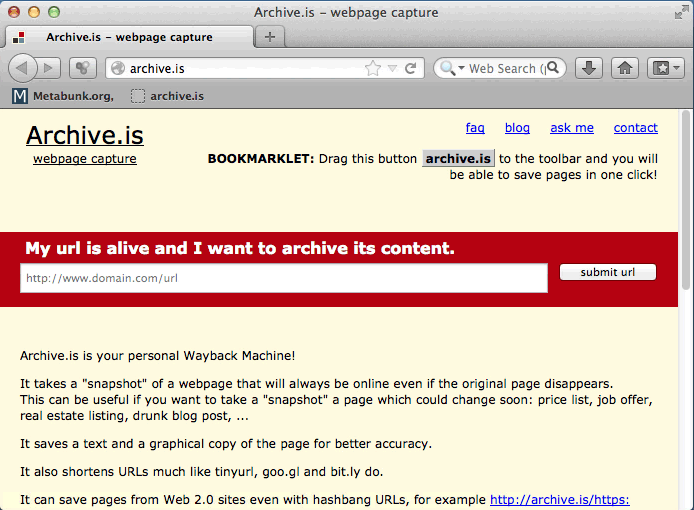
And enter in the URL (or use their bookmarklet)
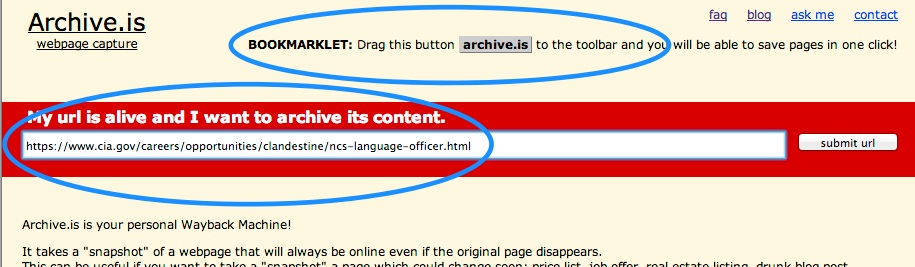
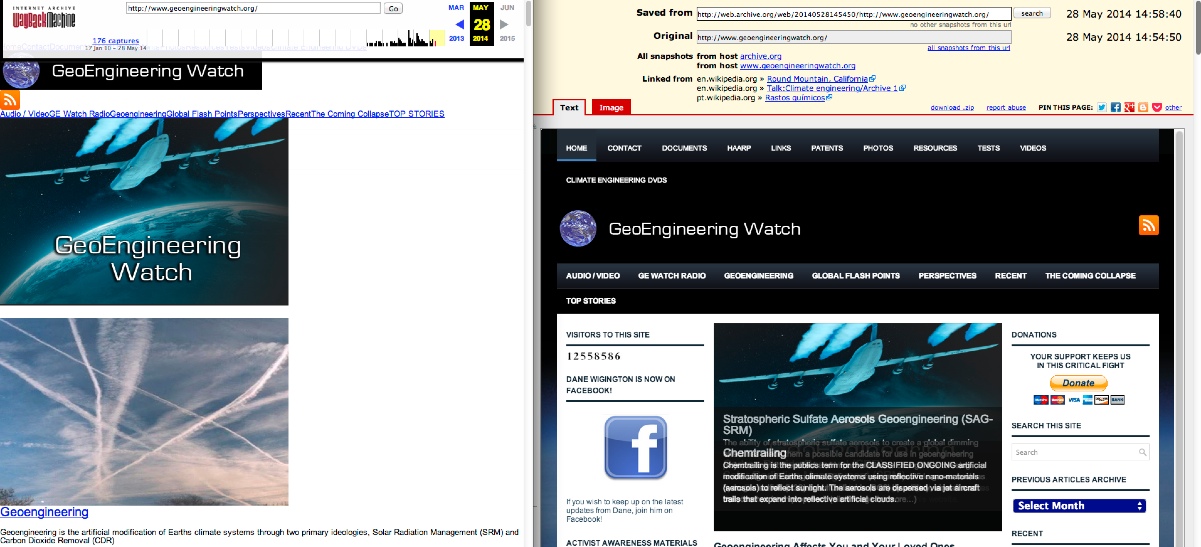
It will do some magic, and you will get a page you can link to that should last for years, with:
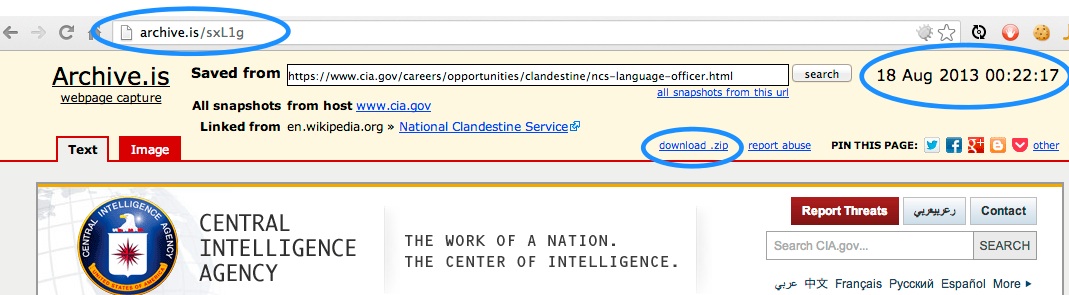
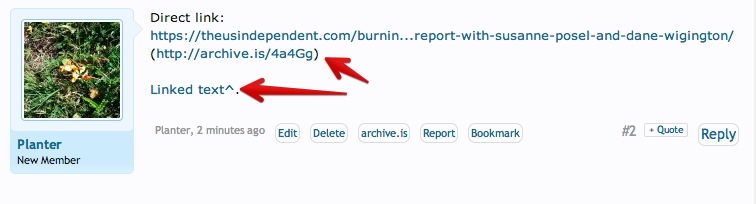
For permanence, click on "download zip", and then attach the file to the post. Like I have done below.
They when you use the link, put the original link in, then archive link after it, like:
https://www.cia.gov/careers/opportunities/clandestine/ncs-language-officer.html (http://archive.is/sxL1g)
Just copy the URL of the page, then go to:
http://archive.today/ (formerly archive.is, as seen in images below. Currently both URLs work)
And enter in the URL (or use their bookmarklet)
It will do some magic, and you will get a page you can link to that should last for years, with:
- Short URL
- The date and time of the capture (UTC)
- A link to "download zip"
For permanence, click on "download zip", and then attach the file to the post. Like I have done below.
They when you use the link, put the original link in, then archive link after it, like:
https://www.cia.gov/careers/opportunities/clandestine/ncs-language-officer.html (http://archive.is/sxL1g)
Attachments
Last edited: