Mackdog
Senior Member.
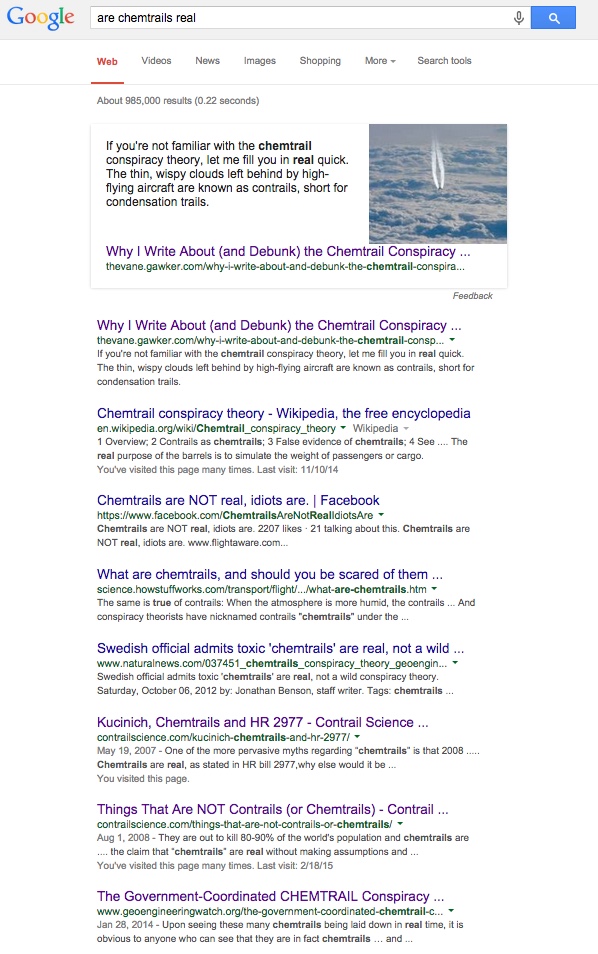
I ran across this today, and apparently Google is thinking about changing the way it filters search results, to more of a debunking type of system. I do not know if this will happen or not, but according to the article, they will be using information from web sites such as Snopes and Factcheck.org to determine if a website will get bumped up or down in the search results.
http://www.newscientist.com/article...es-based-on-facts-not-links.html#.VPMUznysX-v
Makes me wonder if maybe they will start using Metabunk as a source for whether or not a claim or theory should be considered credible. It could happen.The software works by tapping into the Knowledge Vault, the vast store of facts that Google has pulled off the internet. Facts the web unanimously agrees on are considered a reasonable proxy for truth. Web pages that contain contradictory information are bumped down the rankings.
http://www.newscientist.com/article...es-based-on-facts-not-links.html#.VPMUznysX-v