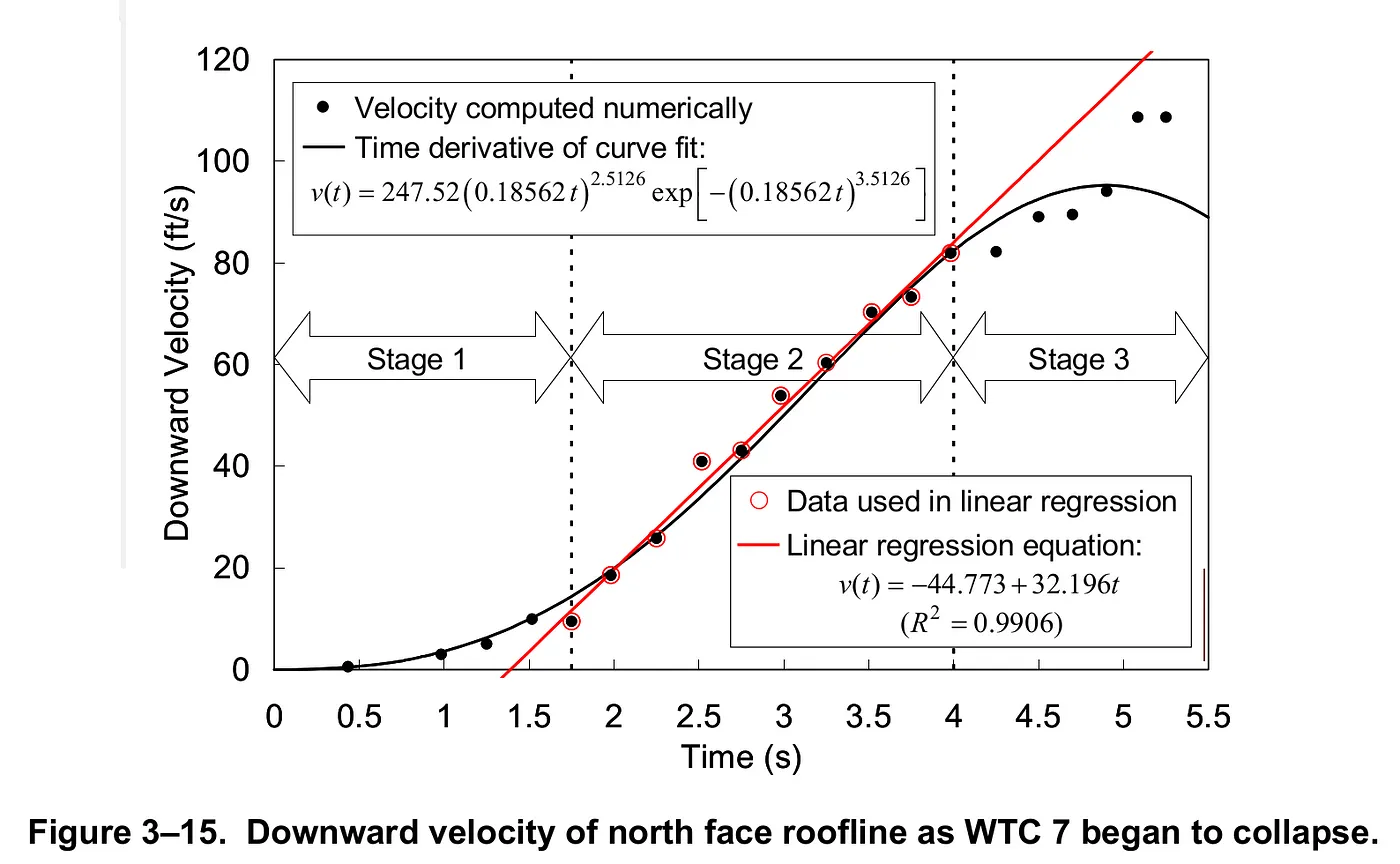
Explain why Chandler's graph, in his careful analysis, shows about 1 second of non-freefall when the roofline starts to descend? If all supports were immediately cut/removed, then why didn't the roofline start free fall at the onset?
To be fair, that could be an artifact of the sampling method and frequency.
Let me construct an example, where I tweek values and units a bit, just to make things numerically easy.
Let's say the video camera snaps a pic 5 times per second.
Let's say g = 10 m/s^2
Let's say descent starts at t = 1.0 s, and is actually immediately in free fall.
If the camera clip starts at 0.0 s, then it will capture that point in time at 1.0 when the descent is just beginning, with h=0 and v=0 in the interval [0.8 s;1.0 s].
In the next frame (t= 1.2 s), h is 0 - 1/2*g*t^2 = -0.5 * 10 m/s^2 * 0.04 s^2 = -0.2 m. v has averaged -0.2 m / 0.2 s = -1 m/s in the interval [1.0 s; 1.2 s]. That's a change of -1 m/s from the previous interval, when v was 0, for an apparent acceleration of -1 m/s / 0.2 s = -5 m/s^2 - half the value of g!
Another 0.2 seconds later, at t=1.4 s, h has dropped to -0.8 m, and v has gone to -0.6 m / 0.2 s = -3 m/s for a change of delta-v = -2 m/s within 0.2 s, which marks an acceleration of 10 m/s^2 - this is finally g!
So, to draw a table
| t (s) | h (m) | v (m/s) | a (m/s^2) |
| 0 | 0 | 0 | 0 |
| 0.2 | 0 | 0 | 0 |
| 0.4 | 0 | 0 | 0 |
| 0.6 | 0 | 0 | 0 |
| 0.8 | 0 | 0 | 0 |
| 1.0 | 0 | 0 | 0 |
| 1.2 | -0.2 | -1 | 5 |
| 1.4 | -0.8 | -3 | 10 |
So it appears in this fictitious dataset that acceleration increases to g only over the course of 0.4 s.
It gets even worse if the descent starts halfway between frames, if, say, the camera's first frame is at 0.1 s, and then 0.3 s, ... 0.9 s, 1.1 s, 1.3 s:
| t (s) | h (m) | v (m/s) | a (m/s^2) |
| 0.7 | 0 | 0 | 0 |
| 0.9 | 0 | 0 | 0 |
| 1.1 | -0.05 | -0.25 | -1.25 |
| 1.3 | -0.45 | -2.00 | -8.75 |
| 1.5 | -1.25 | -4.00 | -10.00 |
The problem is that v always lags behind in Chandler's simple method of just comparing height in consecutive frames. True instantaneous v is -1 m/s at t=1.1 s in my second table, not -0.25. True a is -10 m/s^2 at 1.3 s, not 8.75. Chandler's method, in short, would capture true freefall right from the beginning only after the 3rd frame that follows freefall onset.
And isn't it true (I am too lazy now to check) that Chandler didn't even go frame by frame, as that would be too noisy for him, and instead analyses every 5th or 6th frame?
The problem for all who analyse collapse videos is that true onset of descent is very difficult to capture. At a frame rate of 30/s, and if true onset is at half the time interval between two frames (1/60th of a second before and after the nearest frames), then the first frame after collapse onset, hypothetically in freefall, will find h= -5 m/s^2 * 1/60^2 s^2 = -1.3888 mm (millimeters!).
h(1 s/30 ) = 5.555 mm.
(Oh I am showing four and five relevant digits while working with g = 10 m/s^2

)
It is easy to miss the moment when the collapse of the roofline begins, but it is even more difficult to figure out when a = g begins.
Chandler's data is much too coarse to identify either of those moments.


") "CD did not cause collapse - fires did".)There are many published/posted explanations of how fire caused the collapses. There has NEVER been a valid hypothesis that "proves" (i.e. legitimately hypothesises) that (a) CD Help was needed or (b) CD was performed. In fact no "truther has ever (c) postulated a valid hypothesis as to how the observed collapses (any of the three) could have been achieved by use of CD.
"CD did not cause collapse - fires did".)There are many published/posted explanations of how fire caused the collapses. There has NEVER been a valid hypothesis that "proves" (i.e. legitimately hypothesises) that (a) CD Help was needed or (b) CD was performed. In fact no "truther has ever (c) postulated a valid hypothesis as to how the observed collapses (any of the three) could have been achieved by use of CD.